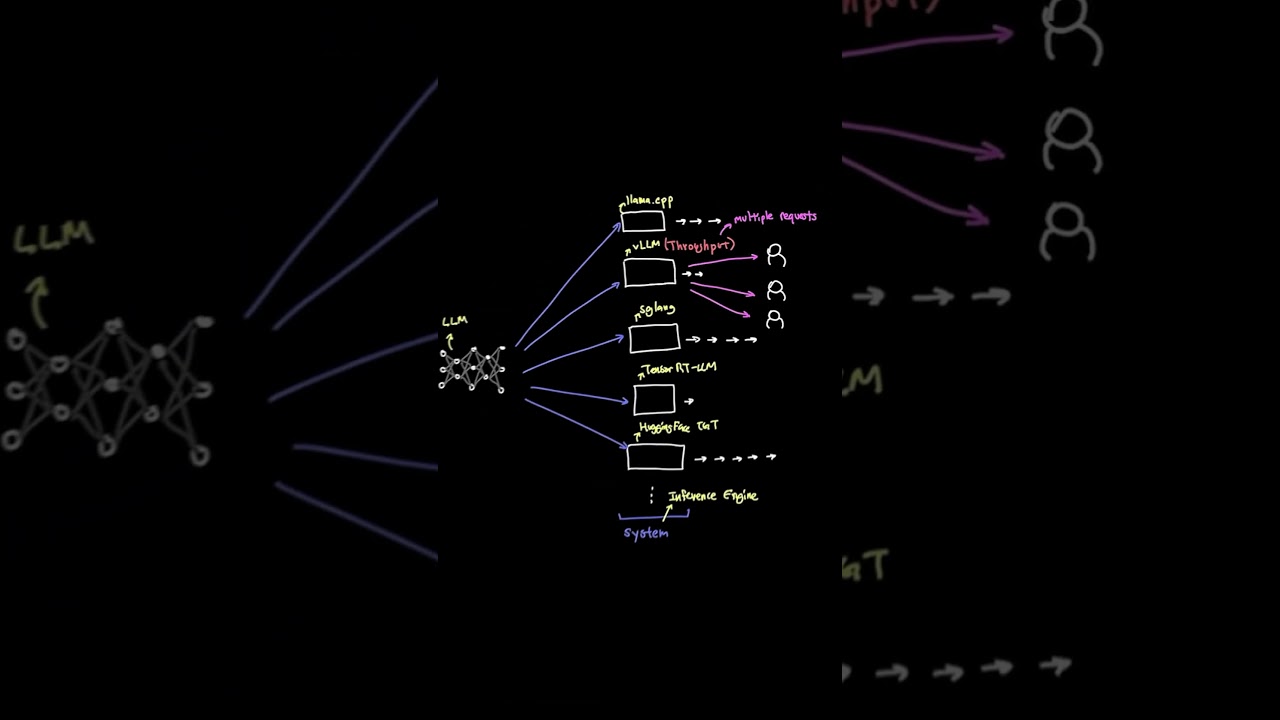
How the vLLM inference engine works?
vLLM isn't just another inference engine, it's the one that finally solved GPU memory waste at scale ?
The problem: every time you serve an LLM, the KV cache has to store each user's conversation context. Old engines blocked off huge memory chunks upfront and wasted most of it. vLLM's PagedAttention changed this by dynamically allocating memory in pages — exactly like how your OS handles virtual memory.
More efficient memory = more requests handled at once = better throughput per GPU.
Follow for more AI & Cloud breakdowns ?
#vLLM #AIInfrastructure #LLMInference #GenerativeAI #PagedAttention #MachineLearning #MLOps #DevOps #GPUOptimization #AIEngineering
The problem: every time you serve an LLM, the KV cache has to store each user's conversation context. Old engines blocked off huge memory chunks upfront and wasted most of it. vLLM's PagedAttention changed this by dynamically allocating memory in pages — exactly like how your OS handles virtual memory.
More efficient memory = more requests handled at once = better throughput per GPU.
Follow for more AI & Cloud breakdowns ?
#vLLM #AIInfrastructure #LLMInference #GenerativeAI #PagedAttention #MachineLearning #MLOps #DevOps #GPUOptimization #AIEngineering

KodeKloud
...